Creando narrativas de datos.
Agenda:
- Empalme.
- Flujos de documentación desde Grafoscopio.
- Desde Lepiter hacia el sistema de archivos.
- Desde HedgeDoc hacia el sistema de archivos.
- Del sistema de archivos a Fossil.
- Del sistemas de archivos a mdBook
Asistentes
- Offray
- choff
- Caos
- ruidajo
- Sara del Mar
- viviana
Notas Varias
Hay personas que creen que ser diseñadora es ser chofer de mouse.
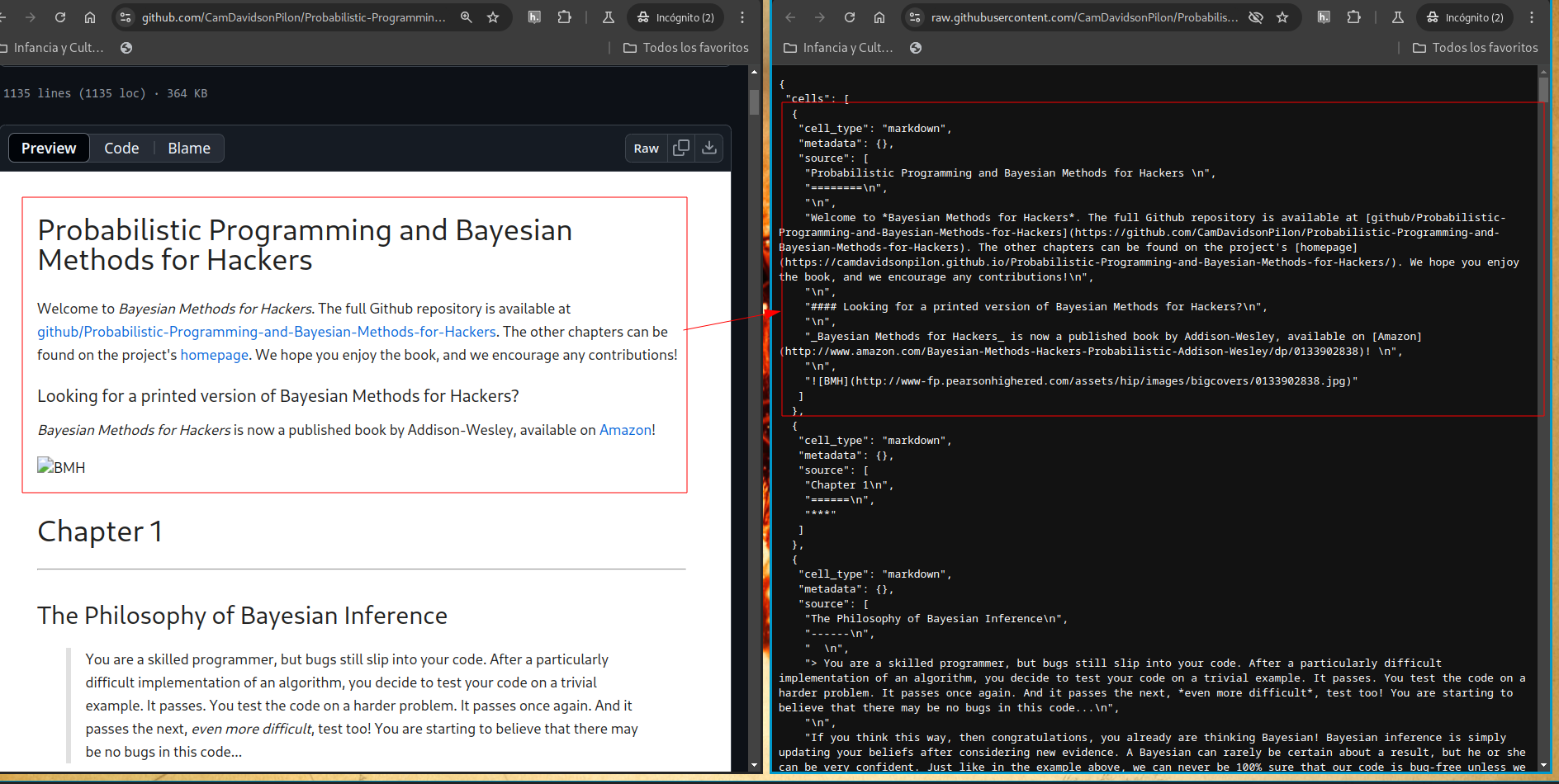
Flujos de documentación desde Grafoscopio
En la sesión anterior digimos que Grafoscopio
permite importar desde la Web, en particular HedgeDoc
y exportar hacia el sistema de archivos.
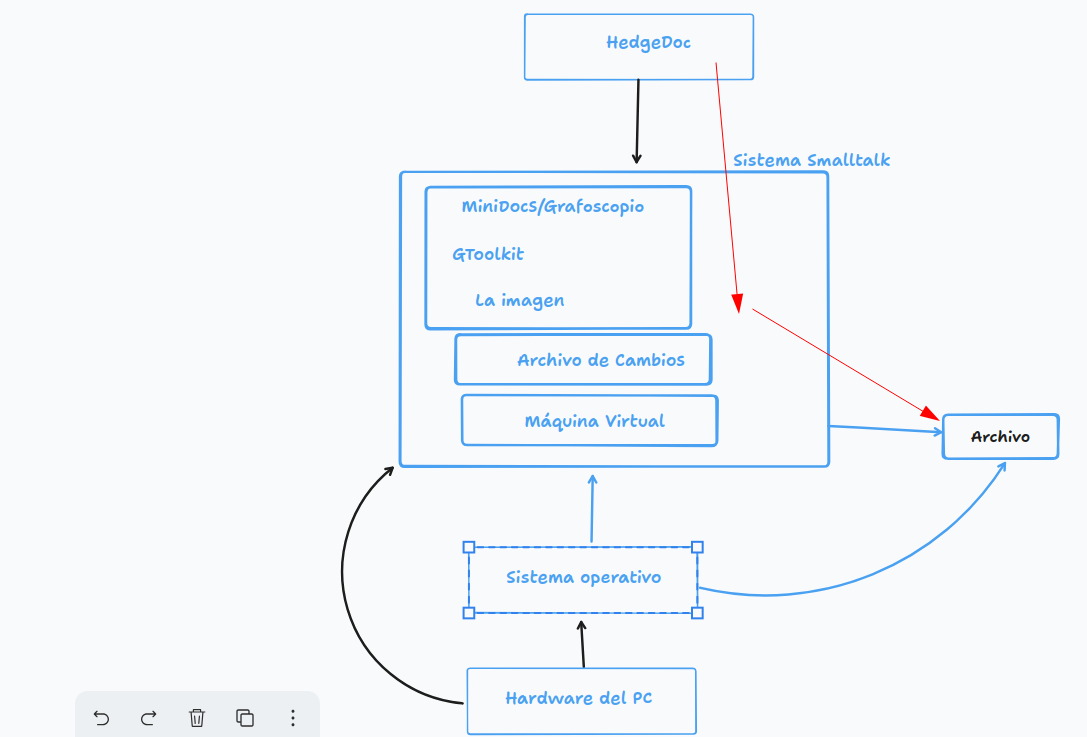
Y lo hicimos con la interfaz gráfica (iconico enactiva).
Ahora veremos cómo hacerlo con la interfaz símbolica (código/comandos)
Para ello creamos nuestra primera narrativa de datos en Lepiter/Grafoscopio.
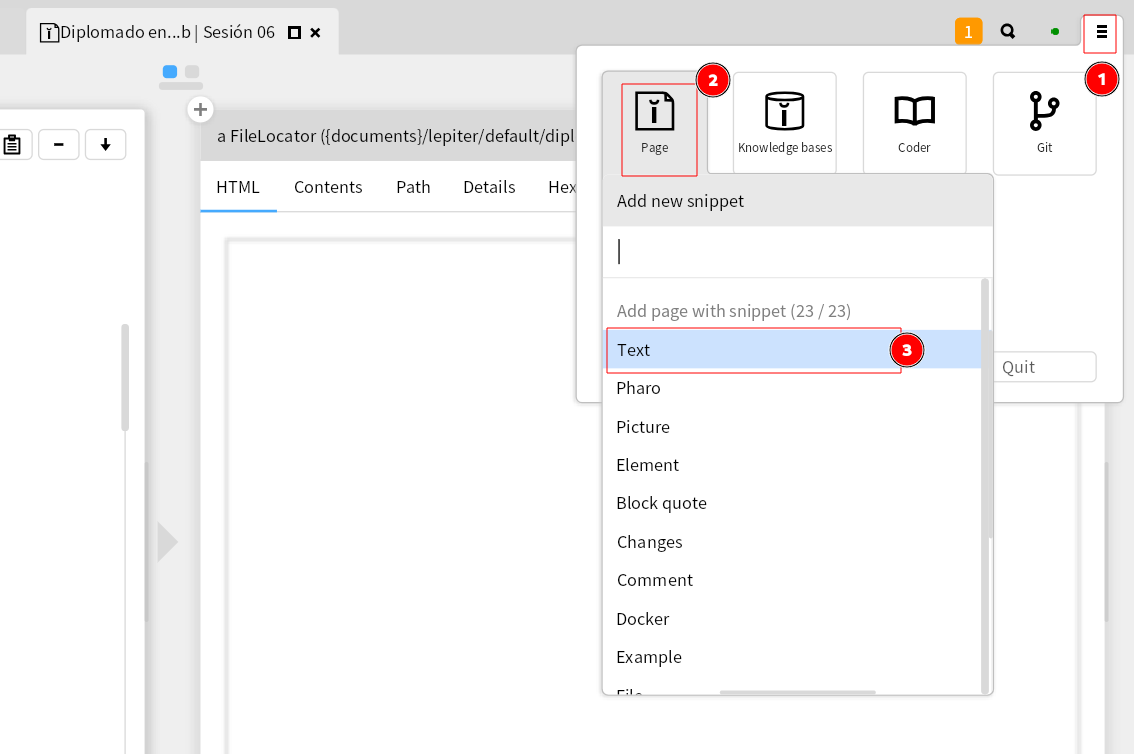
Tendremos entonces una nueva página con un título genérico y en ella podemos reconocer algunos elementos, el título y el primer snippet de texto:
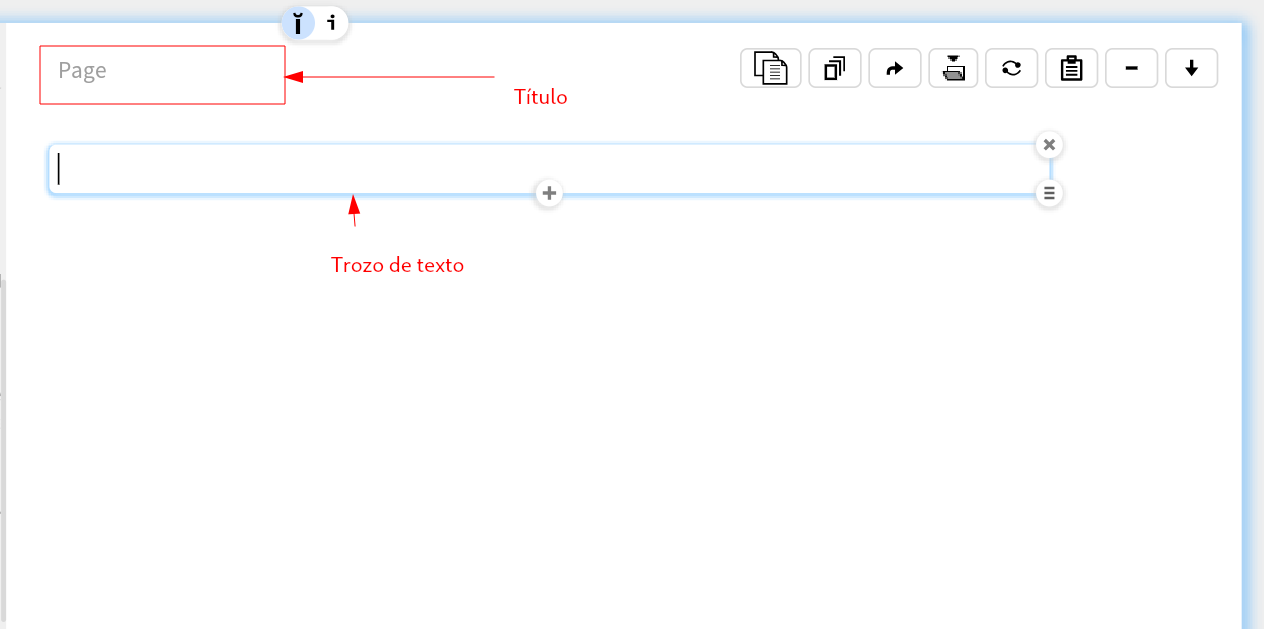
Podemos empezar nuestra página y mostrar algunas de las características interesantes de Smalltalk, en particular su auto-referencialidad:
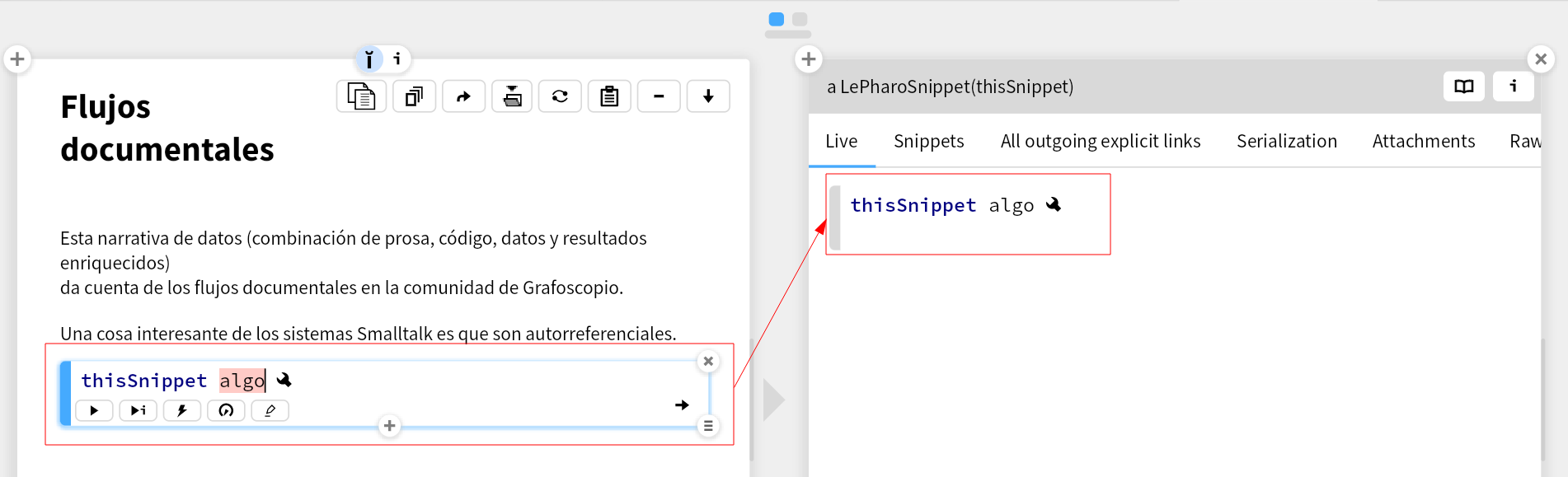
Dado que podemos apelar a la página, podemos apelar al “vocabulario” de la misma.
Es decir a todas las operaciones que se pueden hacer en una página.
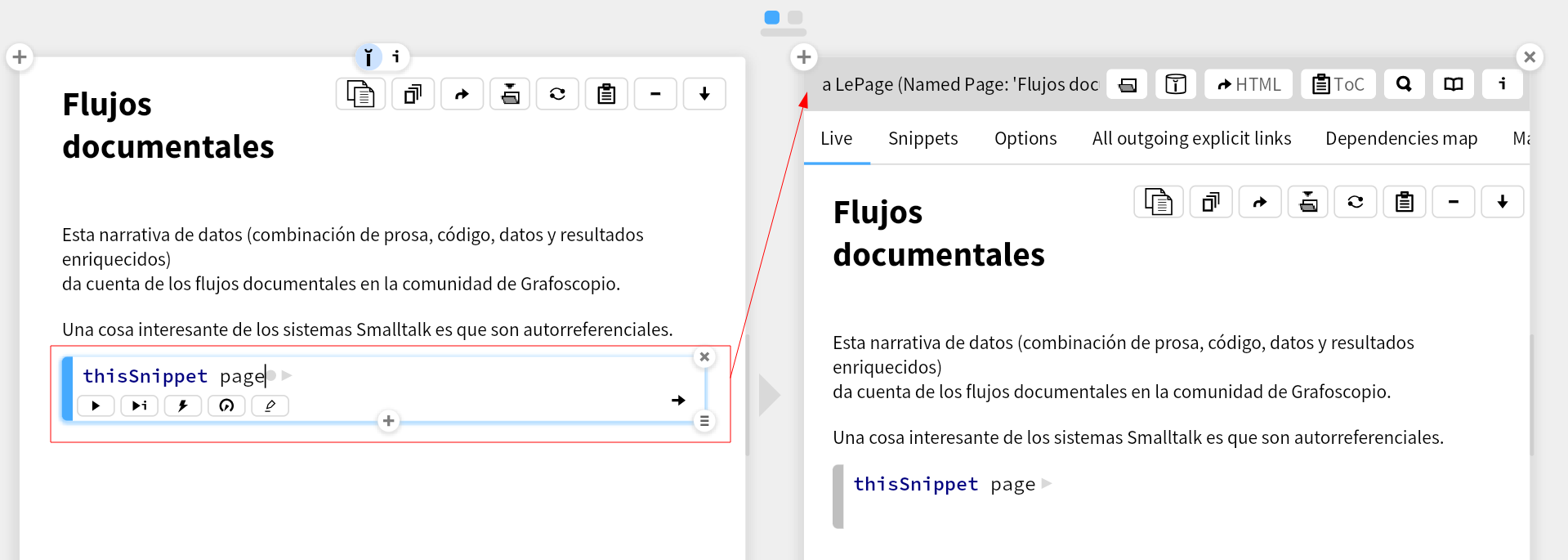
En particular podemos apelar a la operación de exportación de la página,
que veíamos la sesión pasada.
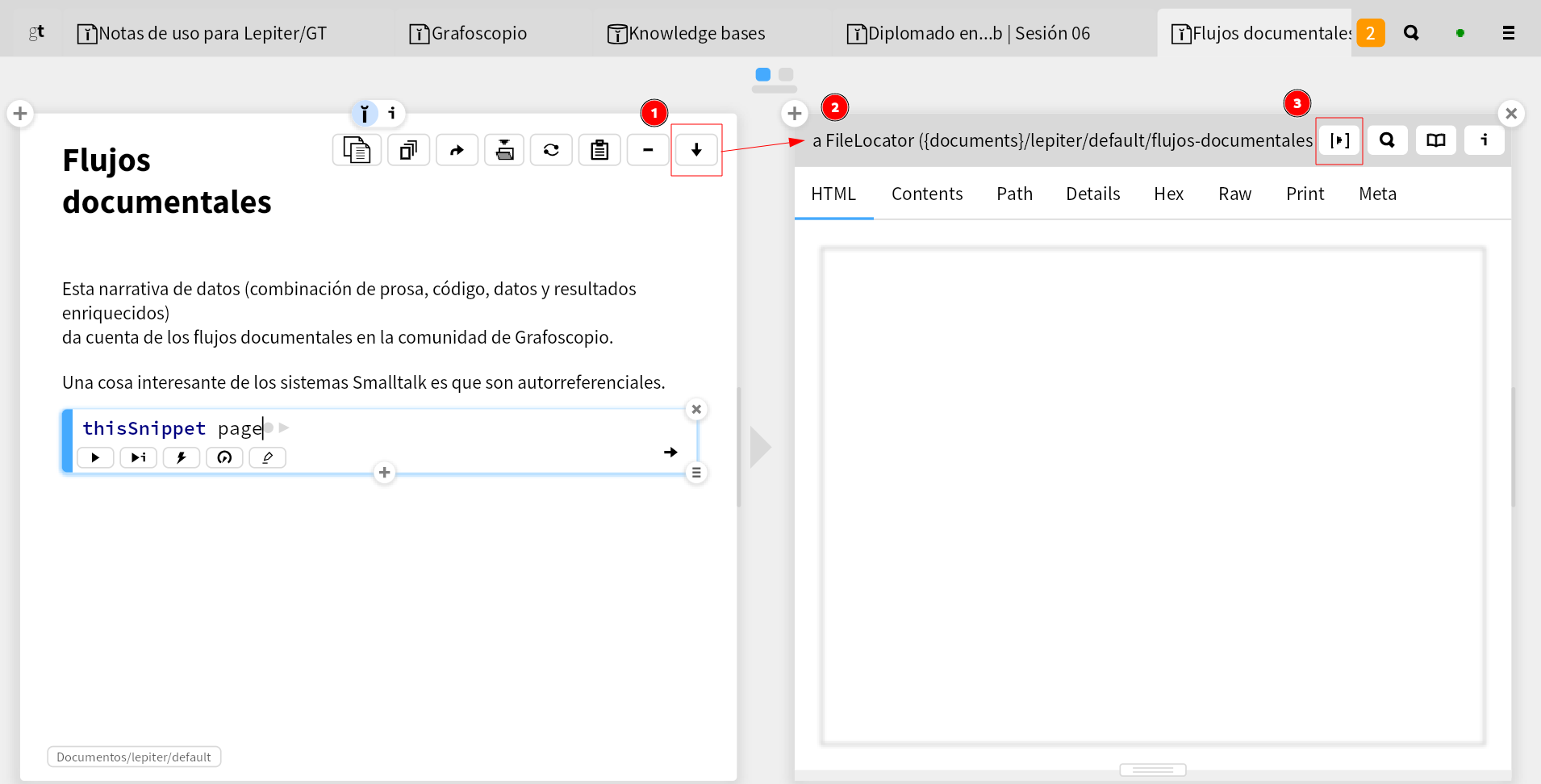
La anterior es una secuencia gráfica de acciones (icónico-enactivo).
El equivalente de eso de manera simbólica sería este:
2 es la forma simbólica de 1. El comando que equivale a hacer los clicks.
También hay un vocabulario para hablar del sistema de archivo:
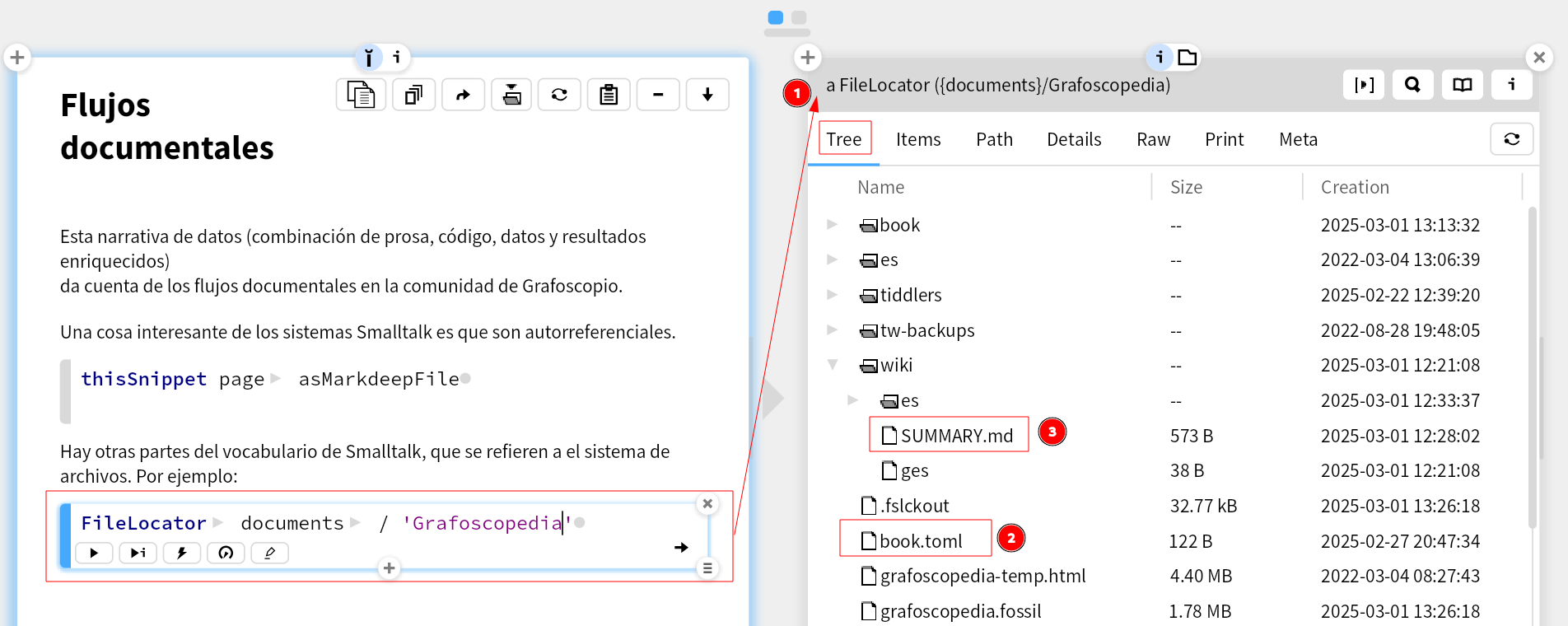
Notemos que algunos elementos con los que hemos venido trabajando,
como el archivo book.toml, la subcarpeta wiki/ o el archivo SUMMARY.md
empiezan a aparecer en la vista del resultado de la ejecución del comando.
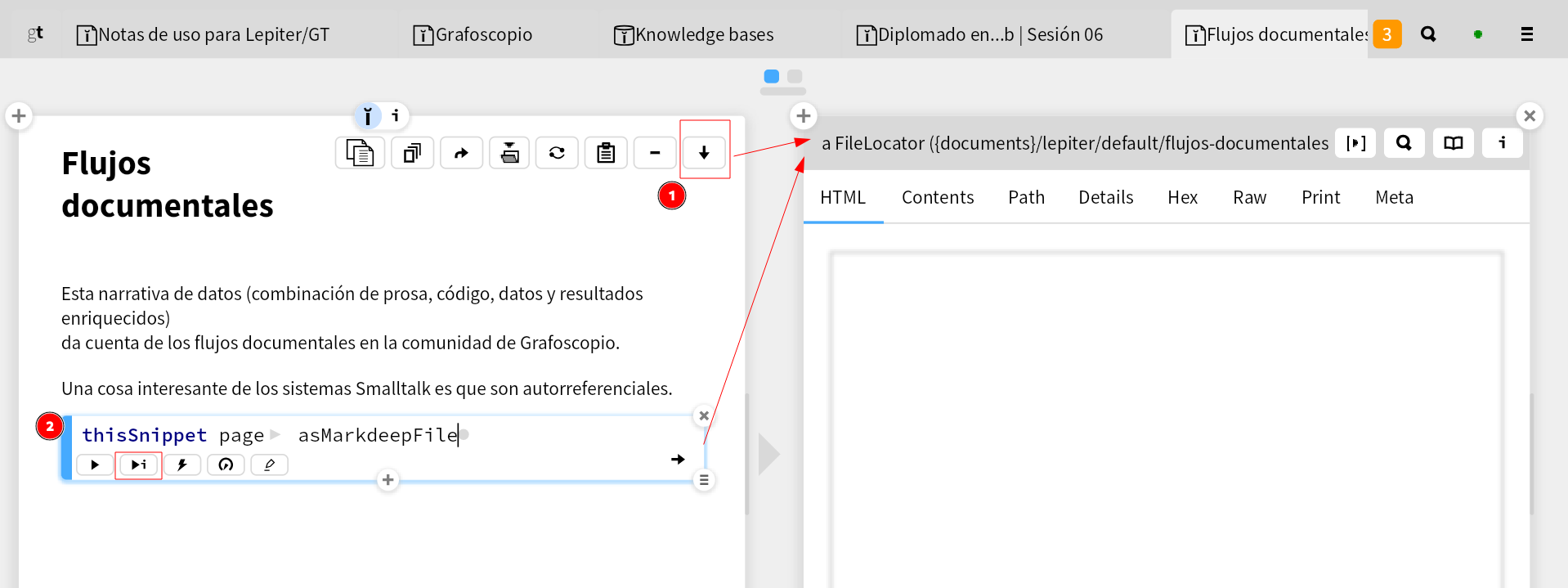
Una cosa clave, que veremos en mayor detalle, es la composición.
Es decir, la creación de comportamientos complejos a partir de algonos más sencillos.
Vamos a componer estos dos elementos que hemos visto del vocabulario.
El documento con dicha composición se puede ver en:
Flujos documentales.
Es posible también importar este documento en nuestra propia imagen.
Preguntas
¿Por qué Markdeep y no Markdown como formato?
Por que es posible verlo directamente en la web sin ninguna herramienta distinta a un navegador web con JavaScript habilitado (casi todos).
Sharing and publishing Pharo powered data stories en la lista de correo de pharo.
Our light format have some differential values over other popular data
stories publishing formats, like Jupyter Notebook:a) Its human and browser readable, in contrast IPynb JSON and Python
exports are readable by one, but not the other.b) it only requires (3mb) Fossil + (350K) Markdeep to be stored, versioned, shared and
published. Other DVCS, web folders can be used and is a big contrast
with complicated and/or oligopolistic support to make a format (Ipynb)
web renderable.c) The same published document can be imported back to
Lepiter. When a Jupyter document is published as HTML, it can not be
imported back from there to Jupyter (I imagine something similar happens
with RStudio or OrgMode, but I have not experienced data workflows on
the last tools by myself).
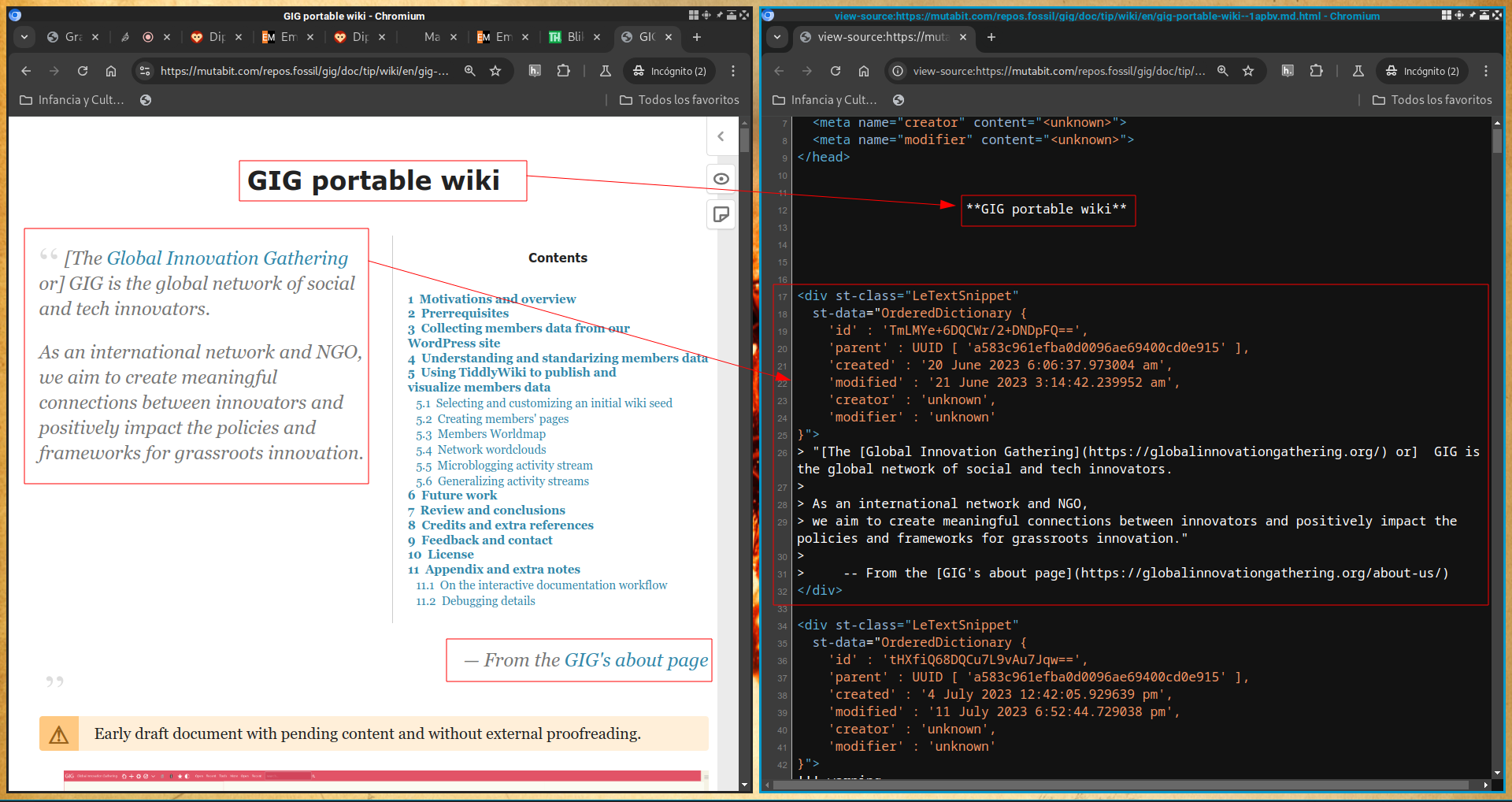
Tomemos la narrativa de datos sobre cómo migrar de WordPress a TiddlyWiki
Veamos el renderizado y su código fuente:
Comparémoslo con el formato de código abierto más popular de narrativas de datos, Jupyter y miremos alguna libreta popular:
https://jupyter.org/try-jupyter/lab/
En contraste el código de Jupyter se ve así: